
Jonathan Andre is a lead ABAP developer at IT Partners. Jon is also the President of Andre Technical Consulting LLC located out of Centreville, Virginia. Jon has over 5 years experience with SAP, with a concentration on ECC SD, MM, and IS-OIL modules. Jon’s focus has been in the areas of ABAP OOP and ABAP Web Dynpro. He can be reached at [email protected]
Chances are that if you work with SAP ABAP, you have heard of SAP HANA by now. You’ve probably heard that it’s “the future” and a “game changer.” You’ve also probably heard that it’s much faster, and it can take tasks that require hours and finish them in minutes. This all sounds wonderful, but technical folks understand that nothing works by magic. What we would like to know is not the what, but the how. What exactly is SAP HANA? How is it able to bring such dramatic improvements to our programs? And finally, how will switching over to SAP HANA impact me as an ABAP developer?
SAP HANA Overview on a Technical Level
SAP HANA is a platform that serves to replace the classical hard disk based data storage system with an in-memory alternative. The SAP HANA Acronym stands for (High-performance ANalytic Appliance). While HANA serves as a replacement for classical hard disk based storage systems, it should be understood that it is more than just a replacement. While HANA can perform any and all features of a traditional DBMS, it also provides many benefits that a classical database server does not. Let’s begin our over overview of SAP HANA by contrasting it to the traditional DBMS.
As a refresher, lets recall how a classical database works. A DMBS manages an array of HDDs that store data in a row based format. Using INSERTS, READS, UPDATES and QUERIES, the database allows users to persist, retrieve, and manage data on demand. The principle drawback of a classical database is the fact that it uses HDDs. Reading, writing, and searching using HDD are an inherent bottleneck to any classical database. Hard disk drives are mechanical devices, requiring a rotating magnetized platter that stores binary data, and a read/write head that accesses and reads that data. (see below)

Although many advances have been made over the years to improve HDD technology speed and storage capability, the HDD can never match the speed of computer memory. Enter SAP HANA and its in-memory data storage. By storing the vast majority of data in memory, HANA sidesteps the costly action of reading data from HDDs to provide data to users. Since retrieving data from computer memory is 100,000 times faster than retrieving data from HDDs on average, the speed increases are exponential and instantaneous. Simply changing the architecture from HDD based tomemory based storage is enough to provide drastic speed increases on its own, but SAP HANA takes it a step further by providing features on top of this in-memory platform. This allows for even greater speed of access, data retrieval, and data processing.
SAP HANA Architecture
SAP HANA and Column Stores
A major difference between SAP HANA and traditional databases is that HANA uses column-store for most database tables, while classical DBs use row-store. The row-store approach works well when you often need to retrieve an entire record from the database at the time, but as ABAP developers know, it is much more common to retrieve a subset of fields during processing. In addition, row-storage often provides only two options when searching a non-primary field. You can either create secondary indexes to speed up data retrieval, or risk performing full table scans when retrieving data outside of the primary index.
Below is an example of how data would be stored in traditional DBMS as rows…
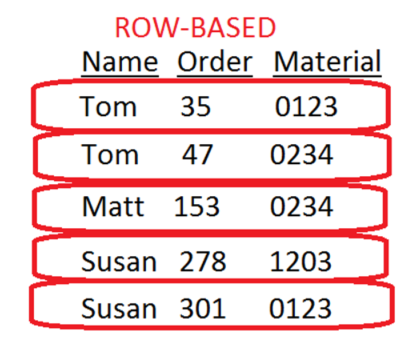
This data would be stored in a traditional database as follows:
001:Tom,35,0123;
002:Tom,47,0234;
003:Matt,153,0234;
004:Susan,278,1203;
005:Susan,301,0123;
Column-store addresses some of these shortcomings of row-store by keeping like fields together. Columnar storage often eliminates the necessity for secondary indexes, because the data is stored in an index-like fashion already. It also allows for common aggregate database functions to be performed much faster. For instance, COUNTs, SUMs, or finding values greater than or less than a particular value can be performed much faster. This is because the like values are stored together in the database, requiring fewer reads to retrieve the data.

In a column based system, the data would be stored as follows:
Tom:001,Tom:002,Matt:003,Susan:004,Susan:005;
35:001,47:002,153:003,278:004,301:005;
0123:001,0234:002,0234:003,1203:004,0123:005;
SAP HANA Data Compression
Another advantage of storing data as columns, which SAP HANA takes full advantage of, is the ability to easily compress data. Compressing data for rows of data can be complicated since you’re often dealing with many different data types for an individual record. The SAP HANA database provides a series of compression techniques that can be used for the data in the column store, both in the main memory and in the persistence. High data compression has a positive impact on runtime since it reduces the amount of data that needs to be transferred from the main memory to the CPU. The compression technique I will explore is based on dictionary encoding, where the column contents are stored as encoded integers in the attribute vector. In this context, encoding means “translating” the content of a field into an integer value. To understand all the different HANA Compression Techniques, RLE, CLUSTER, SPARSE, PREFIX…etc, please see the SAP HANA HELP.
Compressing data from columns is much easier since it is very common for data values to repeat in a table for multiple records. Let’s review an example of this with our previous example database. You will notice that the value Tom and Susan repeat within the table. For the sake of our compression example, let’s assume the “Name” field is of type VARCHAR(10).
Since every character is up to 4 bytes(remember HANA is Unicode Compliant), and every byte is 8 bits, we can do a simple multiplication to determine that our field is 4x8x10 = 320 bits per name field.
Now let’s compare this to a scenario where we are using data compression via Dictionary Encoding:
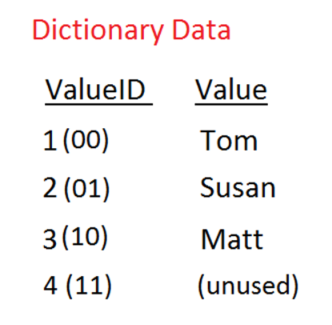
Our example only has 3 distinct names: Tom, Susan, Matt. As such we can represent all the current values in the table with four distinct values (i.e. 00, 01, 02, 03).
Using this information, it’s possible to convert our database table into two distinct tables, while saving space:
Dictionary Table:
Attribute Vector:
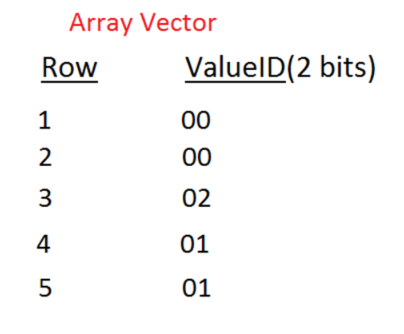
By utilizing of these two tables, we can represent the entire first column in our example database table while taking up less space. An example database query using dictionary-based compression would be done in two steps:
- Query the Dictionary Table to determine the value ID of the desired name.
- Query the Array Vector Table to determine the row number tied to that value ID.
It is easy to imagine the memory savings dictionary compression would have in an example table with thousands to millions of tables. Instead of having to store a 320 bit value for each of these records, we could effectively replace each one of these values with a 2 bit field! This process can be repeated for all columns, although the benefits would decrease for field values that are less repetitive (e.g. order numbers, personal identifiers, etc). This level of memory savings would simply not be possible in a row-based database.
 The “Insert-Only” Database
The “Insert-Only” Database
The downside of this compression technique is that updating the database directly becomes more costly. Inserting, updating, or deleting a record would require decompressing the table, performing the action, and then recompressing it again.
SAP’s solution for this was to implement an “insert-only” approach to database updates. While a database is in use, SAP would use two versions of the database table: the original database table and a delta table. The original table will have all of the original compressed records, while the delta will have the uncompressed records that represent additions and changes.
SAP is able to keep track of the latest (and therefore most up-to-date) versions of a specific record by attaching a transactional ID. Then, when it’s time to SELECT a record, the original table and delta tables are joined and only the most recent record will be returned.
Once the table is no longer in use, the HANA system will consolidate the changes leaving only the most recent records in the compressed version of the table.
ABAP for HANA
Now that we have a basic understanding of SAP HANA and the benefits it provides, we can start to evaluate what it means for us ABAPers and the coding approach on the system. The most important things to understand when developing ABAP on a SAP HANA based system is, that SAP HANA is more than just a database system. Beyond just storing and retrieving data, the SAP HANA can perform many complex operations on the data being retrieved itself. In fact, since the SAP HANA system has been optimized to work with the data in the system, it can perform these operations much faster than the calling ABAP program.
As a result of this fact, a paradigm shift was needed to the programming approach to fully take advantage of all the benefits SAP HANA offers.
DATA-TO-CODE vs. CODE-TO-DATA
The Old Approach – Data-to-Code:
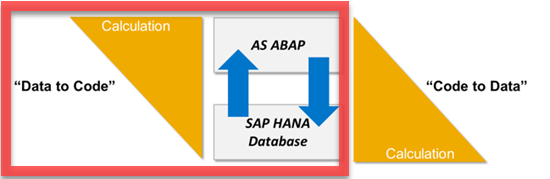
In traditional ABAP coding, it is standard practice to limit hits to the database by bringing in as much data as possible initially, then performing operations on this data. Although retrieving large amounts of data from the database is time consuming, this approach was superior to hitting the database multiple times. Once we have the data within our program (whether it be in variables, internal tables, or your preferred data structure type), we perform operations to produce a file, report, or output.
The HANA Approach – Code-to-Data:
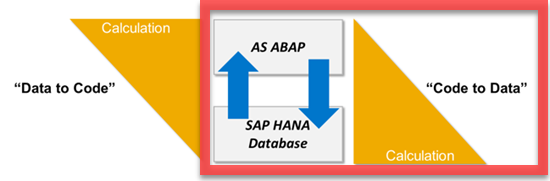
The capabilities of HANA have literally caused the data-to-code approach to be turned upside down. Instead of gathering huge chunks of data and operating on it with ABAP coding logic, HANA’s capabilities insist that you perform data intensive operations to be performed in the database layer itself. To achieve optimal speeds, it makes more sense to “pushdown” your coding logic to the database layer. Once the data intensive operation is performed, only the result would be transferred and used within your ABAP program.
An example of such an operation might be calculating the total sales value to a particular customer over the past 10 years. In traditional ABAP, you would select all sales for that customer into an internal table, then loop through the records while adding the sales together to produce a sum. With HANA however, it makes more sense to push down the loop process to the database layer, perform the summation there, and then only return the resulting total sales value. This has the dual benefit of increasing calculation speed and reducing the amount of data that needs to be transferred from one layer to the next, reducing a potential system bottleneck.
SAP provides a few ways to implement this “code pushdown” approach and, depending on your requirement, you may find one to be more suitable in certain scenarios than others. Lets look at three, OPEN SQL, CDS Views and ABAP Managed Data Procdures (AMDP).
Open SQL
Open SQL allows developers to perform database operations on traditional databases, regardless of the underlying RDBMS. The Open SQL written in ABAP programs is converted by the kernel into Native SQL, and then executed on the actual RDBMS.
The same is true of Open SQL and the HANA database. Our existing Open SQL statements (but not Native SQL, however) will continue to work the SAP HANA DB due to the kernel converting the statements to HANAs native DB language.
To take full advantage of the “code pushdown” functionality, however, it is necessary to use the new Open SQL syntax, which has been enhanced in SAP Netweaver 7.40 SP05 and onwards. This new syntax includes arithmetic, aggregational, and comparative functions that allow operations to be performed at on the database layer (e.g. SUM, COUNT, AMOUNT, CEIL, CASE, etc).
Open SQL is a good option if you are performing a one-off database procedure that you will most likely not be repeating. Here is an example… Note the use of “@” Escape Variables and Inline DATA Declarations
select field1, field2 from db_table where field = @lv_var INTO @DATA(it_result).
Core Data Services Views (CDS)
Core Data Services (CDS) is an SQL like language that provides an open-source Data Definition Language for the creation database artifacts. CDS can be used to create tables, views, data types, and data associations. To do this, you would create an “.hdbdd” file (using the Eclipse editor) and activate the file to generate the associate types and database objects.
CDS Views, which are generated by following the above process, are in many ways like a standard view that would be defined in SE11. The main difference is that, while a view defined in SE11 can only be executed within the SAP system, a CDS view resides on the HANA database itself. Therefore, CDS views can be consumed not only by ABAP programs; but also by non-ABAP applications as well. CDS views are also more powerful than regular SE11 views. All of the operations available to Open SQL statements are also available to CDS Views. This provides a simple and repeatable way for the calling program to take advantage of SAP HANAs powerful features by executing a simple SQL query. CDS Views are best used when dealing with queries that will be repeated across multiple applications. Here is an example…
define view SampleView as select from ExampleTable
With parameters p_field1:<somevalue>,
{
id,
field1,
field2
} where field1 = p_field1;
ABAP Managed Database Procedures (AMDP)
ABAP Managed Database Procedures (AMDP) are specialized ABAP methods that allow the creation of database procedures written in database-specific languages. To use AMDP with HANA, the developer would create a method written in SQLScript that could be directly executed upon in the database layer. Classes that implement AMDP methods are required to implement specific interfaces (in the case of HANA, the interface is IF_AMDP_MARKER_HDB).
The method that actually implements the SQLScript would then need to specify its purpose with specific additions. An example…
METHOD amdp_hdb_ex BY DATABASE PROCEDURE FOR HDB LANGUAGE SQLSCRIPT [TRADITIONAL METHOD ADDITIONS] [SQLSCRIPT CODE] ENDMETHOD.
While Open SQL or CDS Views will usually be enough to perform many Code Pushdown goals, AMDP offers a last resort approach to take full advantage of any SAP HANA features that may not be available by other means.
Summary
So the 64 million dollar question… what changes for application development in ABAP?
Lets recap, at its core, SAP HANA is a modern, main memory-based relational database (in-memory database) that is optimized both for analytical (OLAP) and transactional (OLTP) scenarios. We saw the architecture has changed with HANA and it can no longer be considered just an RDBMS. It is a “PLATFORM” that allows developers to Accelerate, Extend, and most importantly Innovate as they optimize existing migrations to HANA and develop new solutions. We touched on the concept of the new coding paradigm “CODE PUSH-DOWN” and why it is important.
Over the next few blogs, I will be diving deeper into the three primary approaches to Code Pushdown coding. In addition, I will explore what an SAP HANA upgrade means for existing ABAP code

